

SQL Server Pivot is a transformative tool that offers a dynamic approach to reshaping and restructuring data in the ever-evolving field of database management. This article explores the subtleties of SQL Server Pivot, offering a helpful synopsis, background information, benefits, drawbacks, troubleshooting advice, and real-world examples to help you make the most of it.
Table of Contents
Introduction
A strong relational database feature called SQL Server Pivot makes it possible to rotate or convert data from rows into columns. When data needs to be presented in a different orientation, this functionality comes in very handy, improving readability and analytical capabilities.
A Brief Look at History
For many years, the idea of pivoting data has been essential to database systems. Building on this heritage, SQL Server Pivot offers an organized and effective method for achieving data transformation. It has changed over time to meet the ever-changing requirements of contemporary database management.
Advantages and Disadvantages of SQL Server Pivot
The following are the benefits and drawbacks of utilizing the PIVOT operator in SQL Server:
Advantages of SQL Server PIVOT:
Transformation of Data:
PIVOT makes it easier to convert row-level data into a columnar format that is easier to read. When you want to present aggregated data in an organized way, this is very helpful.
Reporting Made Simpler:
Cross-tabular report creation is made easier with PIVOT. For reporting purposes, it’s a useful tool because it makes data easier to understand and analyze.
Generation of Dynamic Columns:
PIVOT enables the creation of dynamic columns based on the values found in the original data. When working with datasets where the number of unique values is not fixed, this flexibility is advantageous.
Capabilities for Aggregation:
Sums, averages, counts, and other aggregate functions can be easily calculated with PIVOT since it allows you to perform aggregations on the pivoted data.
Increased Readability:
PIVOT’s capacity to transform rows into columns can improve the legibility of the output. This is particularly useful when handling complex queries or datasets.
Disadvantages of SQL Server PIVOT:
Restricted to Aggregated Data:
The main purpose of PIVOT is data aggregation. PIVOT might not be the best choice if your query needs a comprehensive, row-level result set.
Names of Static Columns:
Based on the values found in the source data, PIVOT generates static column names. This might be problematic if the dataset changes over time and the query needs to be modified frequently.
Intricate Syntax:
PIVOT query construction can be tricky, particularly for people who are unfamiliar with the syntax. Effective use requires an understanding of the connections between the source data and the intended output.
Aspects of Performance to Consider:
Using PIVOT may affect performance, depending on the size and complexity of the dataset. Assessing the trade-off between enhanced readability and possible performance consequences is crucial.
Limited Command over Formatting of Output:
PIVOT may offer less control over the output formatting than manual data transposing techniques. It might be difficult to meet custom formatting requirements using PIVOT alone.
Common Issues Related to SQL Server Pivot
There are some common problems that users may run into when using SQL Server Pivot. For the PIVOT operator to be used smoothly and effectively, it is imperative to comprehend these problems and how to resolve them. The following are a few typical SQL Server Pivot problems:
Improper Aggregation
Problem: Improper use of aggregation functions can produce unreliable outcomes. Unexpected results can arise from selecting the incorrect aggregation method or from not aggregating when it is required.
Resolution: Depending on the type of data you are pivoting, make sure you use the right aggregation functions (SUM, AVG, COUNT, etc.).
Names for Dynamic Columns:
Problem: It can be difficult to generate dynamic column names based on the data in the source table, particularly if the values are not fixed.
Resolution: To handle column names dynamically based on actual data, think about generating the PIVOT query using dynamic SQL.
Limited Ability to Change Column Order:
Problem: It can be difficult to present data in a way that is user-friendly if the columns in the pivoted result are not arranged in the order that is intended for the output.
Resolution: Using additional logic, reorder columns according to your requirements, or manually specify the columns’ order in the SELECT clause.
Managing NULL Values
Problem: Unexpected gaps in the result set may arise if NULL values in the source data are not handled correctly during the pivoting process.
Resolution: To handle NULL values during aggregation, use the COALESCE or ISNULL functions. Make sure your query considers possible NULL situations.
Effect on Performance:
Problem: Using complicated PIVOT queries or pivoting big datasets may cause performance problems that affect how quickly queries execute.
Resolution: If performance starts to become an issue, assess how well your PIVOT queries are performing, think about indexing, and look into other options.
Restricted to Total Information:
Problem: Since PIVOT is meant to be used for data aggregation, trying to use it for specific, row-level results could result in unintended consequences.
Resolution: If more in-depth information is required, think about utilizing different methods or integrating PIVOT with other query operations.
Gaining Knowledge of Pivot Syntax
Problem: Building a proper PIVOT query necessitates a solid grasp of its syntax, and users who are not familiar with it may find it difficult to formulate effective queries.
Resolution: To enhance your comprehension of PIVOT syntax, consult the documentation, tutorials, and examples. Before taking on complicated scenarios, practice with straightforward cases.
Syntax of Pivot
SELECT * FROM
(SELECT ColumnName1, ColumnName2, PivotColumnName FROM TableName) AS MainData
PIVOT (AggregationFunction(ColumnName1)
FOR PivotColumnName IN (Value1, Value2, Value3,..., ValueN)
) AS PivotTable;Example of PIVOT
Example 1 : Find out territory wise year wise total due
Let’s look at the AdventureWorks2016 database’s Sales.SalesOrderHeader table. To view the total sales amount for each sales representative across various years, we will pivot the data. Here’s an example of a question:
The Sales.SalesOrderHeader table’s required columns, such as TerritoryID, OrderDate, and TotalDue, are chosen by the MainTable subquery.
To extract the year from the OrderDate, we utilize the YEAR function.
The TotalDue column is aggregated for each year (OrderYear) that is specified by the PIVOT clause, and the outcome is shown in the Pivot Table.
SELECT * FROM (
SELECT [soh].[TerritoryID], [st].[Name], YEAR(OrderDate) AS [OrderYear], [TotalDue]
FROM [Sales].[SalesOrderHeader] soh INNER JOIN [Sales].[SalesTerritory] st
ON st.TerritoryID=soh.TerritoryID
) AS MainTable
PIVOT (
SUM(TotalDue)
FOR OrderYear IN ([2019], [2020], [2021], [2022])
) AS PivotTable;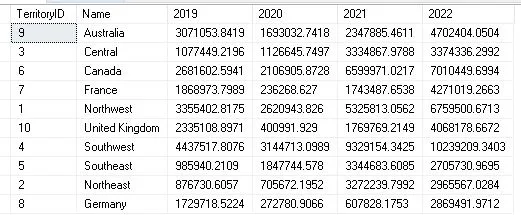
Note: For illustrative purposes, the years [2019], [2020], [2021], and [2022] in the PIVOT operator’s IN clause have been selected. Based on the actual data in your scenario, you can modify them.
Example 2 : Find out total quantity sold by product and sales territory
Now let’s use the AdventureWorks2016 database for another example. This time, the data will be panned to display the total quantity sold of various products across various sales territories. This is the question:
SELECT * FROM (
SELECT [p].[Name] AS ProductName,[t].[Name] AS TerritoryName,[sod].[OrderQty]
FROM [Sales].[SalesOrderHeader] soh
JOIN [Sales].[SalesOrderDetail] sod ON [soh].[SalesOrderID] = [sod].[SalesOrderID]
JOIN [Production].[Product] p ON [sod].[ProductID] = [p].[ProductID]
JOIN [Sales].[SalesTerritory] t ON [soh].[TerritoryID] = [t].[TerritoryID]
) AS MainTable
PIVOT (
SUM([OrderQty])
FOR TerritoryName IN ([Northwest], [Northeast], [Central], [Southwest], [Southeast])
) AS PivotTable;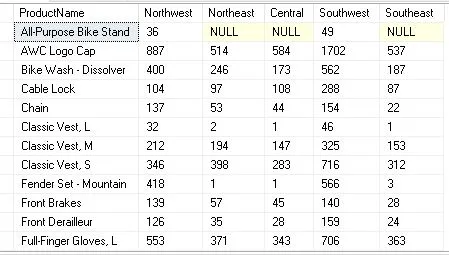
To obtain the product name (ProductName), sales territory name (TerritoryName), and quantity sold (OrderQty), the MainTable subquery joins the SalesOrderDetail, Product, and SalesTerritory tables.
The OrderQty column for each designated sales territory (TerritoryName) is aggregated by the PIVOT clause, and the outcome is shown in the Pivot Table.
Note: For illustrative purposes, the sales territories [Northwest], [Northeast], [Central], [Southwest], and [Southeast] in the PIVOT operator’s IN clause have been selected.
Example 3:
Now let’s use the AdventureWorks2016 database for another example. The data will be panned this time to show the total sales amount for various products and sales years. This is the question:
SELECT * FROM (
SELECT [p].[Name] AS ProductName,YEAR([soh].[OrderDate]) AS SalesYear,
[sod].[LineTotal]
FROM [Sales].[SalesOrderHeader] soh
JOIN [Sales].[SalesOrderDetail] sod ON [soh].[SalesOrderID] = [sod].[SalesOrderID]
JOIN [Production].[Product] p ON [sod].[ProductID] = [p].[ProductID]
) AS MainTable
PIVOT (
SUM(LineTotal)
FOR SalesYear IN ([2019], [2020], [2021], [2022])
) AS PivotTable;
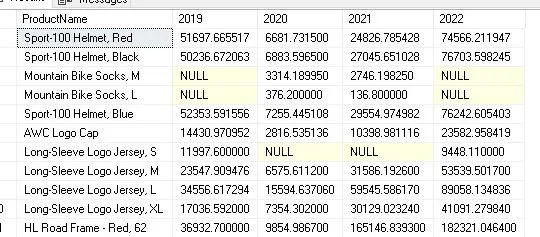
To obtain the product name (ProductName), sales year (SalesYear), and line total sales amount (LineTotal), the MainTable subquery joins the SalesOrderHeader, SalesOrderDetail, and Product tables.
The LineTotal column for each given sales year (SalesYear) is aggregated by the PIVOT clause, and the outcome is shown in the Pivot Table.
Note: The IN clause of the PIVOT operator has selected the years [2019], [2020], [2021], and [2022] for illustrative purposes. In your case, adjust them according to the real sales years.
Conclusion
Although SQL Server Pivot is an effective tool for data transformation, users may run into issues with syntax, performance, aggregation, and dynamic column names. It takes careful consideration of query requirements, best practices, and data characteristics to address these problems. To guarantee the precision and effectiveness of PIVOT queries in a variety of scenarios, regular testing and validation are essential.
FAQs
Q: What is the objective behind SQL Server Pivot?
Ans: Rows are converted into columns using SQL Server Pivot to enhance data analysis and presentation.
Q: Can I use dynamic column values with SQL Server Pivot?
Ans: For additional flexibility, dynamic column values can be used in conjunction with dynamic SQL techniques.
Q: Does SQL Server Pivot make changes to the initial data?
Ans: No, SQL Server Pivot just presents the data in a different format without changing the original data.
Q: Is there anything to consider regarding performance when using SQL Server Pivot?
Ans: Using SQL Server Pivot excessively can affect performance, particularly when working with big datasets. It is imperative to evaluate the trade-offs.
Q: Is it possible to pivot data using more than one column?
Ans: Yes, pivoting data based on multiple columns is supported by SQL Server Pivot, enabling complex transformations.
Q: How should I manage NULL values when pivoting?
Ans: To handle NULL values during the pivot process, you can use the COALESCE or ISNULL functions.
Q: Does pivoting data require the use of an aggregation function?
Ans: Aggregation functions are frequently used in pivot queries, but they are not required. You can even use the NULL function or other functions.
Q: Which other options are there for SQL Server Pivot?
Ans: CASE statements, dynamic SQL with dynamic column names, and visual data representation tools like Power BI are some alternatives.
Q: Is it possible to use temporary tables with SQL Server Pivot?
Ans: Indeed
Q: I have multiple columns. Can I use the PIVOT operation on each one at the same time?
Ans: By adding more columns to the FOR clause, you can pivot on more than one column. The output will contain a distinct set of pivot columns for each extra column.
Q: When using PIVOT, how do I handle null values?
Ans: You can use the COALESCE or ISNULL functions in your pivot query to handle null values. This aids in substituting desired or default values for null values.
Q: Is it possible to utilize dynamic columns in the PIVOT function?
Ans: It’s true that dynamic pivoting entails the use of dynamic SQL to create the PIVOT query dynamically, giving users the freedom to choose columns at runtime depending on the state of the data.
Q: Does PIVOT function with data types other than numbers?
Ans: It is possible to use PIVOT with data types other than numbers. For aggregation purposes, however, the values being pivoted have to belong to the same data type.
Q: In SQL Server, how can I unpivot data?
Ans: You can turn columns into rows by using the UNPIVOT function. The columns are to be unpivoted and the matching values column must be specified.
Q: Can I use aggregate functions other than COUNT, SUM, AVG, and so on with PIVOT?
Ans: Sure, PIVOT supports several aggregate functions, such as MIN, MAX, and others. Based on the needs you have for your data analysis, select the suitable aggregate function.
Q: What performance factors should be taken into account when applying PIVOT to big datasets?
Ans: Performance may be impacted by pivoting big datasets. Make sure all columns used in the PIVOT operation are properly indexed, and take into account how this will affect memory usage and execution strategies.
Q: Is it possible to utilize PIVOT with table variables or temporary tables?
Ans: It is possible to use PIVOT with temporary tables and table variables. Before utilizing the PIVOT function, make sure that all required columns are specified.
Q: How can I create column names in the PIVOT query dynamically?
Ans: Dynamic SQL can be used to create dynamic column names. Create the PIVOT query dynamically, adding the required column names according to the requirements or conditions of the data.
Q: Does PIVOT function with every SQL Server version?
Ans: SQL Server 2005 and later versions do support PIVOT. Make sure the syntax you use is appropriate for the version of the software you are working with.
Q: Can I combine GROUP BY clauses with PIVOT?
Ans: It is possible to combine GROUP BY clauses with PIVOT. When you want to further group the data before pivoting, this is helpful.
Q: Is it possible to UNPIVOT several columns at once?
Ans: By naming them in the UNPIVOT operation’s IN clause, you can UNPIVOT multiple columns. The unpivoted output will contain separate rows for each column.
Q: How can I deal with null values when the UNPIVOT function is running?
Ans: The COALESCE or ISNULL functions in the UNPIVOT query can be used to handle null values. This enables you to set a default or desired value in place of null values.
Q: Can non-numeric data types be used to UNPIVOT data?
Ans: Non-numeric data types are compatible with UNPIVOT. For consistent outcomes, make sure the values being unpivoted are of the same data type.
Q: Can I create column names on the fly while the UNPIVOT process is running?
Ans: The UNPIVOT query can be generated with dynamic SQL to achieve dynamic column names. This gives you the freedom to choose columns at runtime depending on the state of the data.
Q: Can table variables or temporary tables be used with UNPIVOT?
Ans: It is possible to use UNPIVOT on temporary tables and table variables. Before utilizing the UNPIVOT function, make sure that all required columns are defined.
Q: How can previously PIVOTed data be UNPIVOTED?
Ans: By performing the UNPIVOT operation on the PIVOT operation’s output, you can UNPIVOT data that has already been PIVOTed. Make sure the data types and columns match correctly.
Check the below articles also:
DBCC Freeproccache in SQL Server: A powerful command
Understand Deadlocks in SQL Server
Unleash Database Insights with Extended Events in SQL Server